Our manuscript is published at Imaging Neuroscience https://direct.mit.edu/imag/article/doi/10.1162/imag_a_00071/118937
Connectome-based Predictive modeling
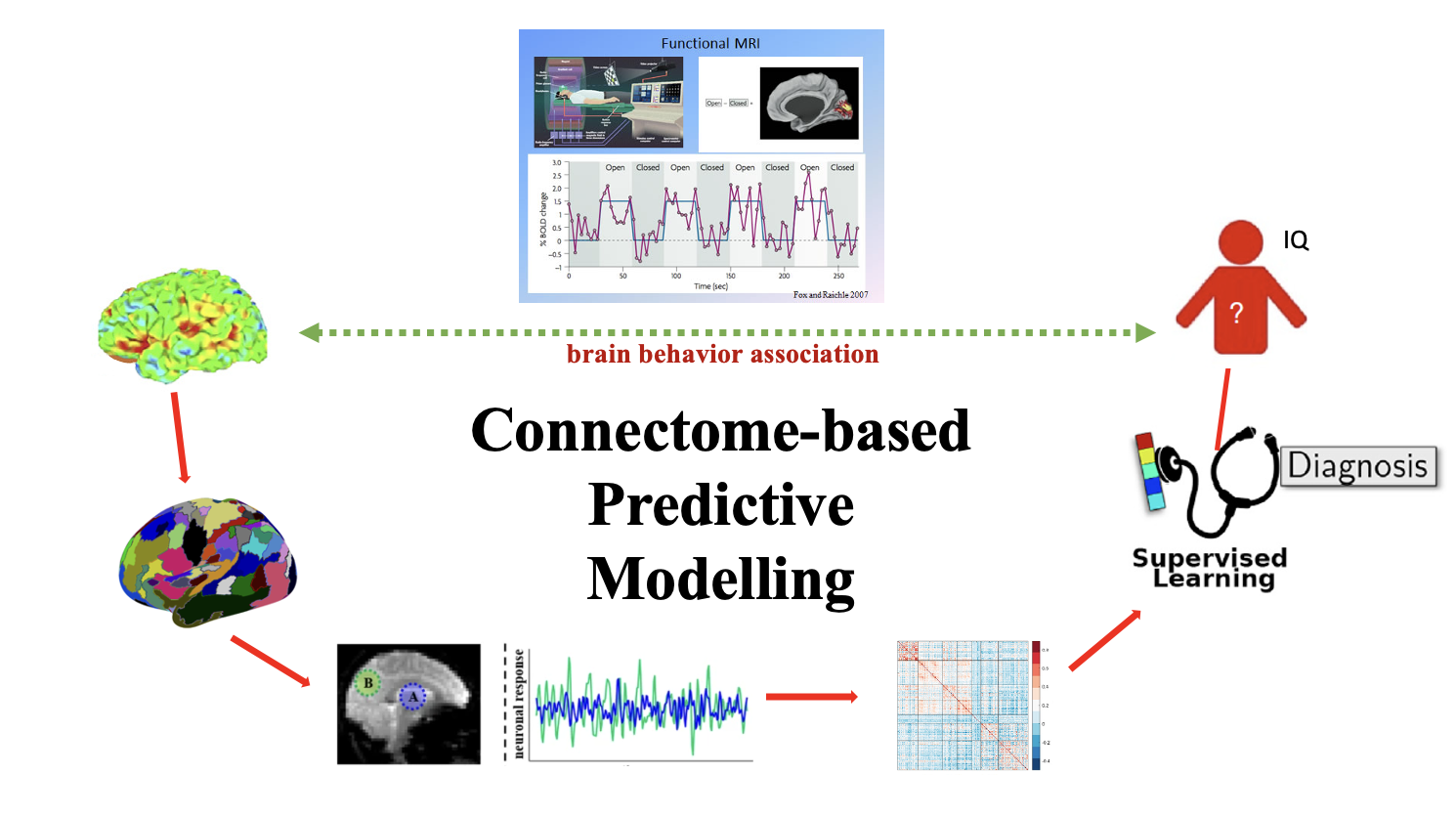 Figure 1. Flowchart of Connectome-based Predictive modeling in neuroimage analysis.
Figure 1. Flowchart of Connectome-based Predictive modeling in neuroimage analysis.
Connectome-based Predictive Modeling (CPM) is a technique in neuroscience that predicts individual behaviors, cognitive abilities, and disease states from brain connectivity patterns. The neuroimaging data is first preprocessing and parcelated using brain atlas. Connectome is then generated by the correlaiton of average functional Magnetic resonance imaging (fMRI) timeseries between nodes or tracking the white matter fibers in Diffusion Tensor Imaging (DTI). As a bridge between neuroscience and data science, CPM offers profound insights into the brain’s role in behavior and disease, highlighting its potential for advancing personalized medicine and targeted treatments in neurological and psychiatric disorders.
Method
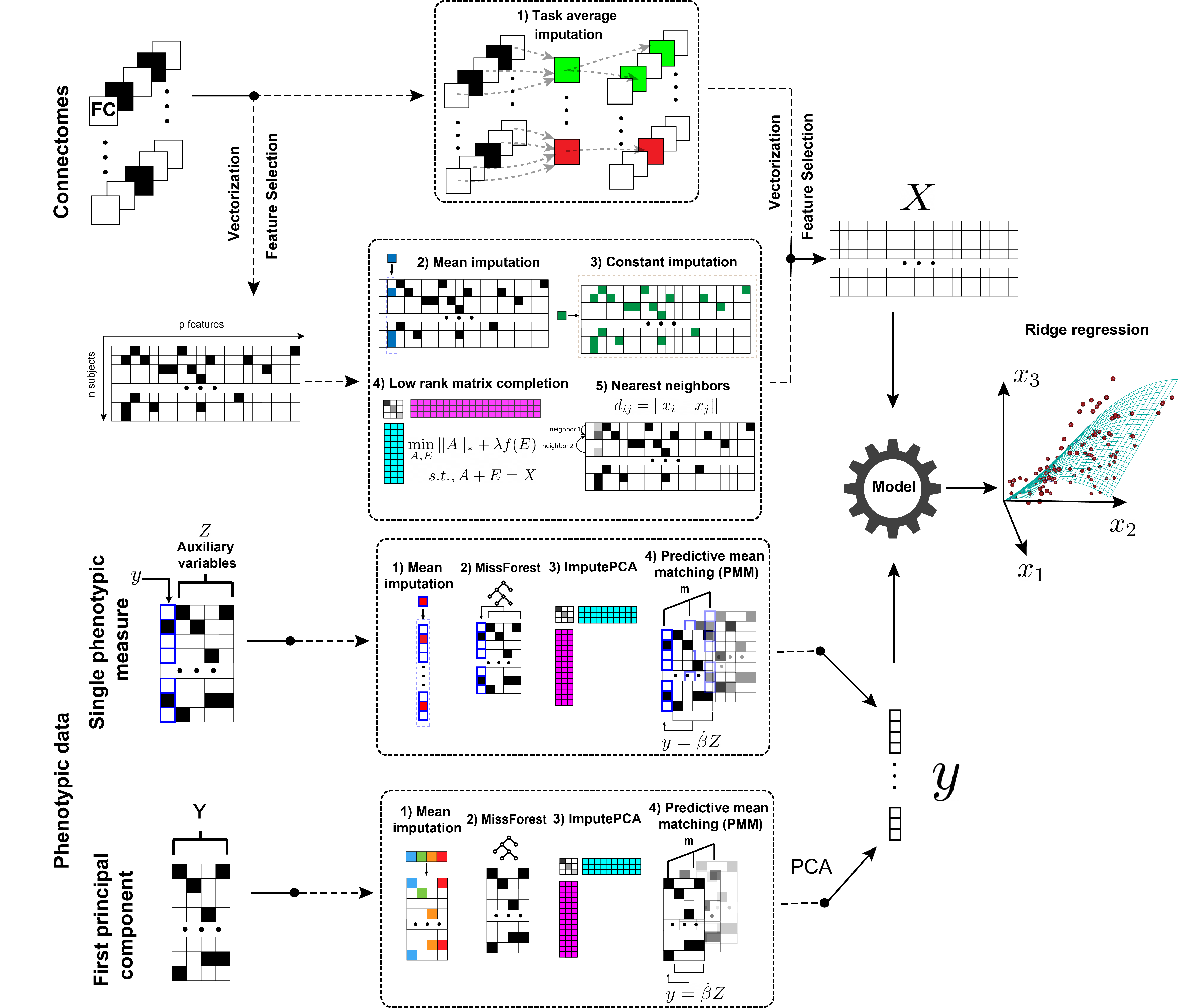 Figure 2. Predictive modeling framework for handling missing data. Missing connectomes are rescued using 1) Task average replacement, 2) Mean imputation, 3) Constant value imputation, 4) Robust Matrix Completion, or 5) Nearest Neighbors imputation. Missing phenotypic measures are imputed with auxiliary variables using 1) Predictive mean matching (PMM), 2) ImputePCA, 3) MissForest, or 4) Mean imputation. The phenotypic and connectivity data are then used in standardized predictive models such as ridge regression or support vector machine. The black squares represent missing data.
Figure 2. Predictive modeling framework for handling missing data. Missing connectomes are rescued using 1) Task average replacement, 2) Mean imputation, 3) Constant value imputation, 4) Robust Matrix Completion, or 5) Nearest Neighbors imputation. Missing phenotypic measures are imputed with auxiliary variables using 1) Predictive mean matching (PMM), 2) ImputePCA, 3) MissForest, or 4) Mean imputation. The phenotypic and connectivity data are then used in standardized predictive models such as ridge regression or support vector machine. The black squares represent missing data.
Validation methods
Models were evaluated using 10-fold cross-validation. Complete-case analysis served as the baseline. Participants with missing data (\(X\) or \(y\)) were included only in the training set. The testing set consisted only of participants with complete data. Additionally, we assessed models on participants with missing X by randomly splitting all participants into training and testing sets. Notably, missing data from the training and testing sets were imputed independently to prevent data leakage. A feature selection threshold of p < 0.01 was used to select features in the training set. The ridge regression hyper-parameter was determined by grid searching using nested 5-fold cross-validation within the training set. For regression, the model performance was evaluated by the cross-validated \(R^2\), \(R^2_{CV}=1-\sum_{i=1}^n(y_i-\hat{y})^2/\sum_{i=1}^n(y_{i}-\bar{y})^2\). \(R^2_{CV}\) can be negative, which suggests the predictive model performs worse than simply guessing the mean of the phenotypic measure. In this case, we set it to 0. For classification, the model performance was evaluated by each fold’s average Area Under the Receiver Operating Characteristic Curve (ROC AUC).
Datasets
Four datasets were used in our study: the Human Connectome Project (HCP) 900 Subject Release, the UCLA Consortium for Neuropsychiatric Phenomics (CNP), the Philadelphia Neurodevelopmental Cohort (PNC) and the Healthy Brain Network (HBN).
Results
Imputing missing connectomes improves prediction performance
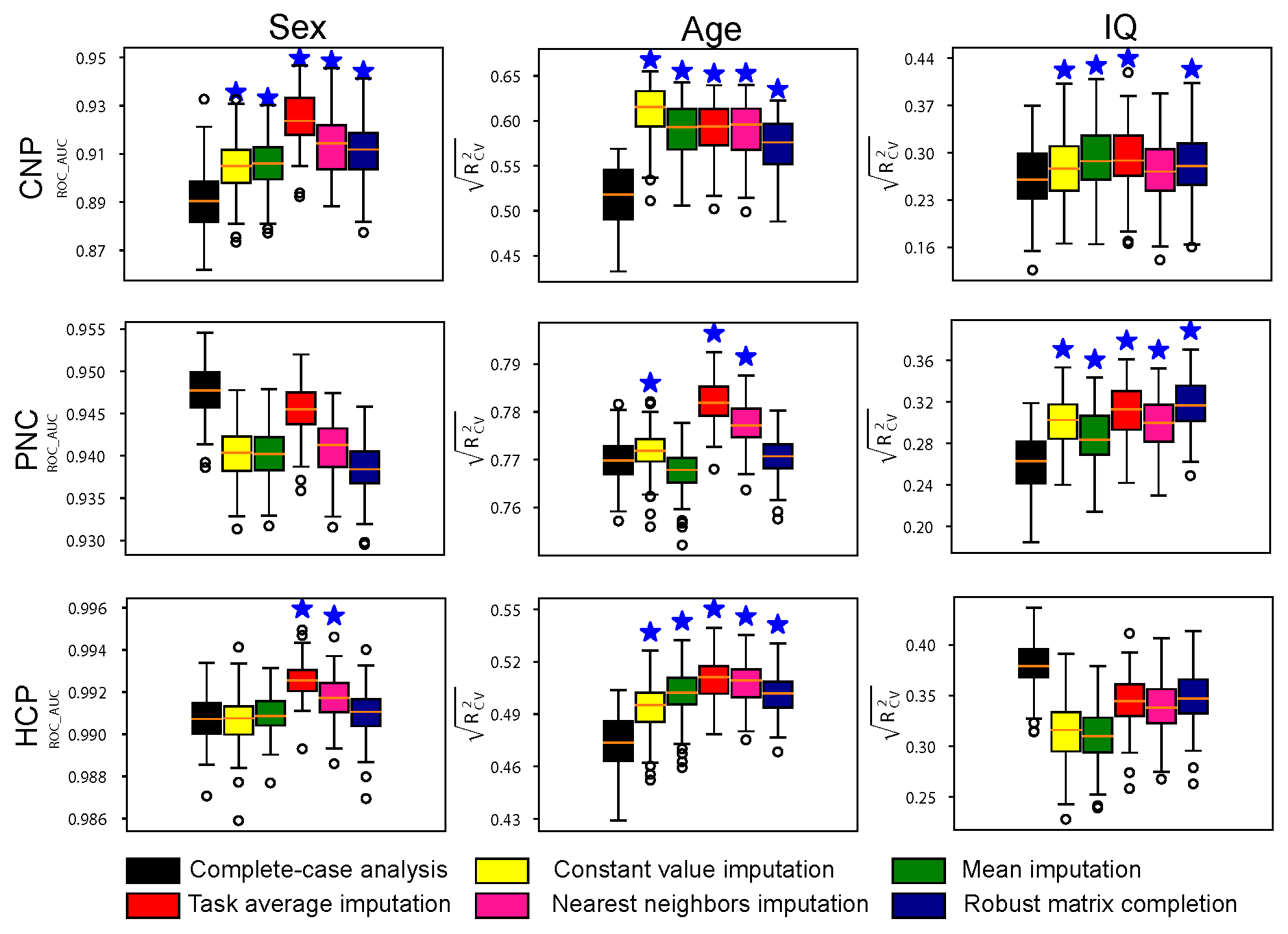 Figure 3. Prediction performance of models built on datasets with missing connectome data. The testing set only includes participants with complete data. Prediction performance of sex, age and fluid intelligence based on data imputed using multiple imputation strategies in three datasets, including CNP, PNC and HCP. Stars above the boxplots indicate a significantly higher prediction performance relative to complete-case analysis (p < 0.001).
Figure 3. Prediction performance of models built on datasets with missing connectome data. The testing set only includes participants with complete data. Prediction performance of sex, age and fluid intelligence based on data imputed using multiple imputation strategies in three datasets, including CNP, PNC and HCP. Stars above the boxplots indicate a significantly higher prediction performance relative to complete-case analysis (p < 0.001).
Using real missing data, we investigated if imputing missing connectomes improves prediction performance. Fig. 2 presents the prediction performance of phenotypic measures (sex, age, IQ) based on complete-case data and data imputed using multiple methods. Our results demonstrate that imputing missing data can significantly improve prediction accuracy compared to models built on complete data, in most cases. For sex classification, all models achieved high accuracy (>0.9) across all three datasets.
Imputing missing phenotypic data improves prediction performance
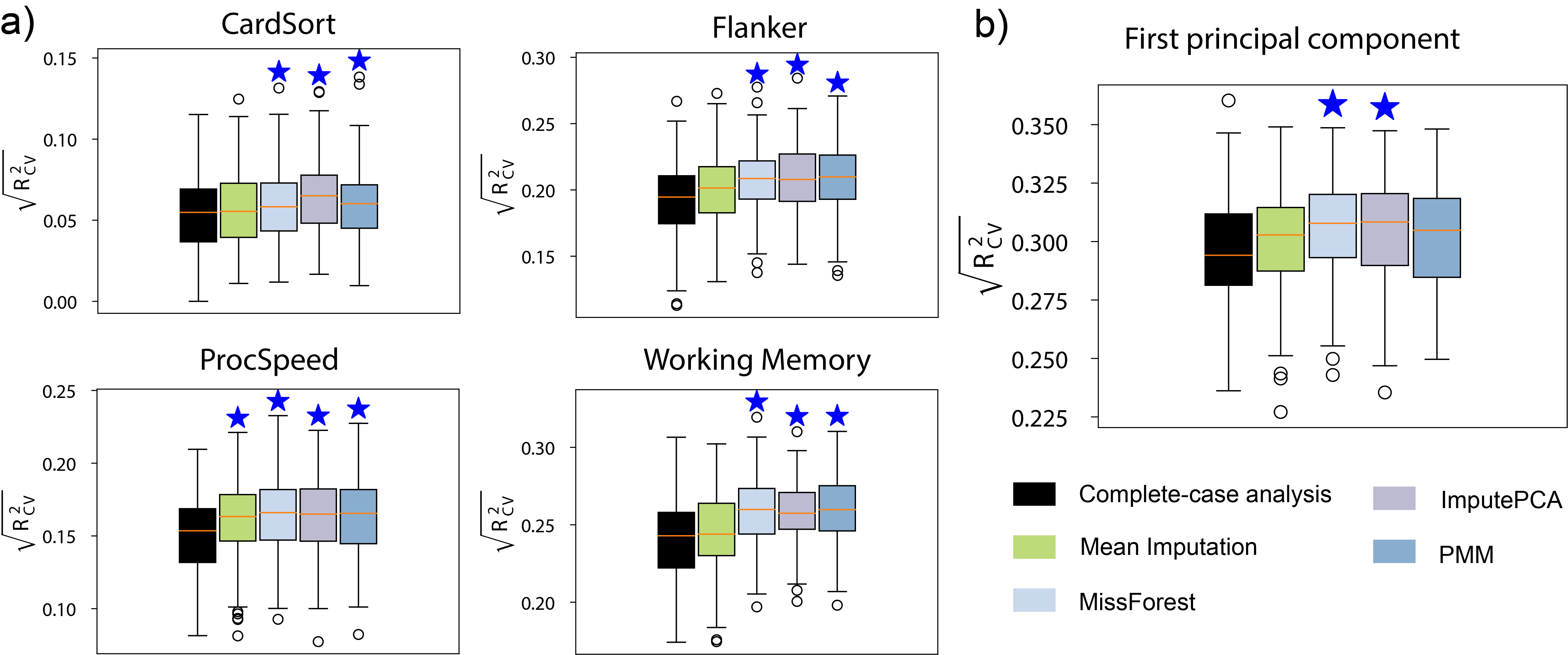 Figure 4. Prediction performance of models built with HBN participants with missing phenotypic measures. a) Performance of predicting a single cognitive measure. b) Performance of predicting the first principal component of ten cognitive measures.
Figure 4. Prediction performance of models built with HBN participants with missing phenotypic measures. a) Performance of predicting a single cognitive measure. b) Performance of predicting the first principal component of ten cognitive measures.
In the HBN dataset, a substantial number of participants have missing connectomes and cognitive measures. Through imputation, we were able to rescue several participants: 33 for CardSort, 34 for Flanker, 42 for ProcSpeed, and 54 for Working Memory. For predicting the first principal component of ten cognitive measures, 195 participants were rescued by imputing the missing cognitive measures. Only participants with missing data were included in the training set, and the prediction performance was evaluated on the same testing set used for complete-case analysis. As depicted in Figure 4 a and b, imputing missing cognitive measures significantly improved the prediction performance compared to complete-case analysis. Among the four imputation methods used, mean imputation yielded the lowest prediction performance.
Imputing missing connectomes and missing phenotypic data to rescue the maximum amount of data
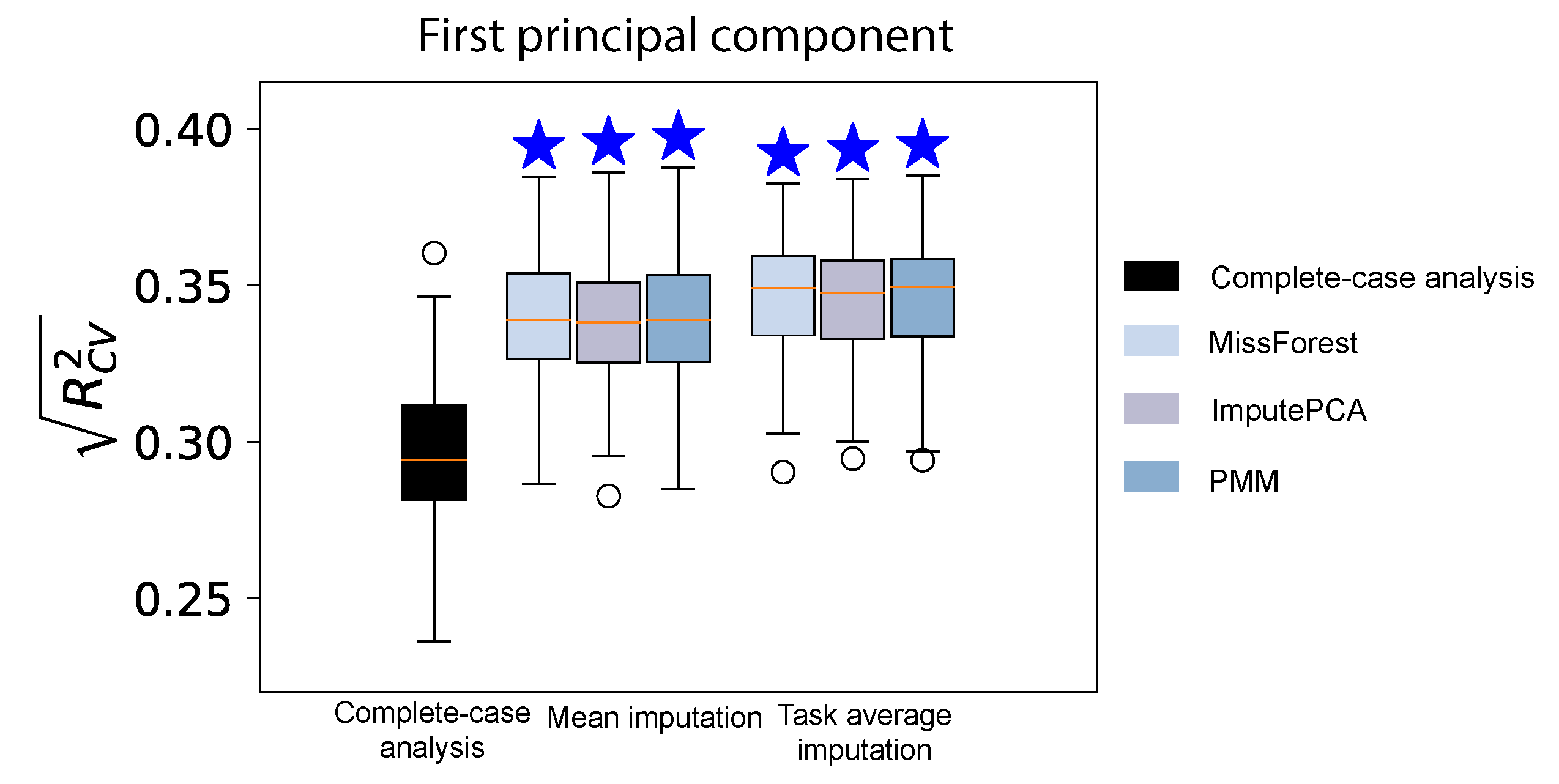 Figure 5. Prediction performance of models built with HBN participants with both missing connectomes and missing phenotypic measures. Missing connectomes were imputed using mean imputation and task average imputation. Missing cognitive measures were imputed using MissForest, ImputePCA, and PMM. In this example, we predicted the first principal component of ten cognitive measures from the HBN dataset.
Figure 5. Prediction performance of models built with HBN participants with both missing connectomes and missing phenotypic measures. Missing connectomes were imputed using mean imputation and task average imputation. Missing cognitive measures were imputed using MissForest, ImputePCA, and PMM. In this example, we predicted the first principal component of ten cognitive measures from the HBN dataset.
Finally, we present a real-world example of the benefits of data imputation in predicting cognition in the HBN dataset. In this example, we predicted the first principal component of ten cognitive measures. The prediction performance in the complete case was 0.295±0.024. 628 participants were rescued by imputing both the missing cognitive measures and connectomes. For imputing missing connectome data, we employed two simple methods: mean imputation and task average imputation. However, due to its inferior performance, meaning imputation was not used for imputing missing cognitive measures. The prediction performance was significantly greater when including the imputed data in the training set (Figure. 5). The combination of task average imputation and MissForest achieved the highest prediction performance (0.347±0.018). Overall, correlation between observed and predicted was ~20% greater and explained variance was ~45% greater after including imputed data in the training set.